grep
参数
-A<显示行数>: 除了显示符合范本样式的那一列之外,并显示该行之后的内容。
-B<显示行数>: 除了显示符合样式的那一行之外,并显示该行之前的内容。
-C<显示行数>: 除了显示符合样式的那一行之外,并显示该行之前后的内容。
-c: 统计匹配的行数
-e: 实现多个选项间的逻辑or 关系
-E: 扩展的正则表达式
-f FILE: 从FILE获取PATTERN匹配
-F: 相当于fgrep
-i --ignore-case #忽略字符大小写的差别。
-n: 显示匹配的行号
-n: 搜索结果显示行号
-o: 仅显示匹配到的字符串
-q: 静默模式,不输出任何信息
-r: 递归查找
-s: 不显示错误信息。
-v: 显示不被pattern 匹配到的行,相当于[^] 反向匹配
-w: 匹配 整个单词
常用法
查找不区分大小写
grep -rni memcpy .
在搜索结果中用反向匹配”-v“排除*.o.cmd文件的匹配
grep -rn memcpy | grep -v .o.cmd
使用多个-v依次对上一次的结果进行反向匹配
grep -rn memcpy | grep -v .o.cmd | grep -v .s.cmd | grep -v .o | grep -v .map
使用-Ev一次进行多个反向匹配搜索
grep -rn memcpy | grep -Ev '\.o\.cmd|\.s\.cmd|\.o|\.map'
使用”--exclude=GLOB“来指定排除某些格式的文件,如不在“*.cmd”,“*.o”和“*.map”中搜索
grep -rn --exclude=*.cmd --exclude=*.o --exclude=*.map memcpy
跟“--exclude=GLOB”类似的用法有“--include=GLOB”,从指定的文件中搜索,如只在“*.cmd”,“*.o”和“*.map”中搜索
grep -rn --include=*.cmd --include=*.o --include=*.map memcpy
“--include=GLOB”在不确定某些函数是否被编译时特别有用
grep -rn --include=*.o rpi_is_serial_active
不在某些指定的目录查找
grep -rn --exclude-dir=out memcpy
忽略多个目录
grep -rn --exclude-dir=out --exclude-dir=doc memcpy
查找精确匹配结果
grep -rnw memcpy .
查找作为单词分界的结果
grep -rn -E "(\b|_)memcpy(\b|_)"
查看查找结果的上下文想看宏定义“MEMCPY”匹配的前三行和后两行
grep -rn -B 3 -A 2 MEMCPY
find命令先找出makefile类文件,然后再从结果中搜索CFLAGS
find . -iname Makefile -o -iname *.inc -o -iname *.mk | xargs grep -rn CFLAGS
grep -rn --include=Makefile --include=*.inc --include=*.mk CFLAGS .
在linux目录中查找所有的*.h,并在这些文件中查找“SYSCALL_VECTOR”
find linux -name *.h | xargs grep "SYSCALL_VECTOR"
打印出所有包含”SYSCALL_VECTOR”字符串的文件名
find linux -name *.h | xargs grep -l "SYSCALL_VECTOR"
grep的选项-l只打印匹配的文件名
实战脚本
#!/usr/bin/env bash
#echo <<<EOT > test.txt
#aaaa
#bbbbbb
#AAAaaa
#BBBBBASDABBDA
#EOT
------------------------sleepAndExecDebug() {
set +x
sleep 1
set -x
}
tee test.txt > /dev/null <<EOT
aaa
bbbbbb
AAAaaa
BBBBBASDABBDA
EOT
echo "aaa" > grep.txt
# cat grep.txt
grep -A2 b test.txt
------------------------sleepAndExecDebug
grep -B1 b test.txt
------------------------sleepAndExecDebug
grep -C1 b test.txt
------------------------sleepAndExecDebug
grep -c aaa test.txt
------------------------sleepAndExecDebug
grep -e AAA -e bbb test.txt
------------------------sleepAndExecDebug
grep -in b test.txt
------------------------sleepAndExecDebug
grep -o ASDA test.txt
------------------------sleepAndExecDebug
grep -q aa test.txt
------------------------sleepAndExecDebug
grep -v aaa test.txt
------------------------sleepAndExecDebug
grep -w aaa test.txt
------------------------sleepAndExecDebug
grep -f grep.txt test.txt
正则表达式
. 匹配任意单个字符,不能匹配空行
[] 匹配指定范围内的任意单个字符
[^] 取反
[:alnum:] 或 [0-9a-zA-Z]
[:alpha:] 或 [a-zA-Z]
[:upper:] 或 [A-Z]
[:lower:] 或 [a-z]
[:blank:] 空白字符(空格和制表符)
[:space:] 水平和垂直的空白字符(比[:blank:]包含的范围广)
[:cntrl:] 不可打印的控制字符(退格、删除、警铃...)
[:digit:] 十进制数字 或[0-9]
[:xdigit:]十六进制数字
[:graph:] 可打印的非空白字符
[:print:] 可打印字符
[:punct:] 标点符号
实战
#!/usr/bin/env bash
------------------------sleepAndExecDebug() {
set +x
sleep 1
set -x
}
echo "aaa" > grep.txt
tee test.reg.txt > /dev/null <<EOT
abc
123
//[
EOT
tee test.reg2.txt > /dev/null <<EOT
ggle
gogle
google
goooooooooooooooooooooooooogle
gagle
EOT
grep . test.reg.txt
------------------------sleepAndExecDebug
grep [a/] test.reg.txt
------------------------sleepAndExecDebug
grep [^abc] test.reg.txt
------------------------sleepAndExecDebug
grep [[:alnum:]] test.reg.txt
------------------------sleepAndExecDebug
grep [a-z] test.reg.txt
------------------------sleepAndExecDebug
grep [[:space:]] test.reg.txt
------------------------sleepAndExecDebug
grep [[:punct:]] test.reg.txt
------------------------sleepAndExecDebug
grep "g[o]*gle" test.reg2.txt
------------------------sleepAndExecDebug
grep "g[o].*gle" test.reg2.txt
------------------------sleepAndExecDebug
grep "g[o]\?gle" test.reg2.txt
------------------------sleepAndExecDebug
grep "g[o]\+gle" test.reg2.txt
------------------------sleepAndExecDebug
grep "g[o]\{1,2\}gle" test.reg2.txt
------------------------sleepAndExecDebug
grep -E "g[o]{10,}gle" test.reg2.txt
------------------------sleepAndExecDebug
egrep "g[o]{,10}gle" test.reg2.txt
位置锚定
^ 行首锚定,用于模式的最左侧
$ 行尾锚定,用于模式的最右侧
^PATTERN$,用于模式匹配整行
^$ 空行
^[[:space:]].*$ 空白行
\< 或 \b 词首锚定,用于单词模式的左侧
\> 或 \b 词尾锚定;用于单词模式的右侧
\<PATTERN\>
实战
#!/usr/bin/env bash
------------------------sleepAndExecDebug() {
set +x
sleep 1
set -x
}
tee test.reg3.txt > /dev/null <<EOT
aaa
bbbbbb
acdfsddsfb
EOT
------------------------sleepAndExecDebug
grep ^a test.reg3.txt
------------------------sleepAndExecDebug
grep b$ test.reg3.txt
------------------------sleepAndExecDebug
grep ^$ test.reg3.txt
------------------------sleepAndExecDebug
grep ^[[:space:]].*$ test.reg3.txt
------------------------sleepAndExecDebug
grep "\<a.*b\>" test.reg3.txt
分组和后向引用
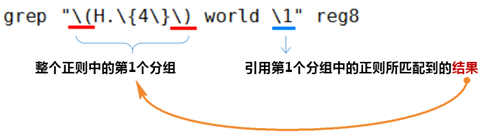
① 分组:() 将一个或多个字符捆绑在一起,当作一个整体进行处理 分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部的变量中,这些变量的命名方式为: \1, \2, \3, … ② 后向引用 引用前面的分组括号中的模式所匹配字符,而非模式本身 \1 表示从左侧起第1个左括号以及与之匹配右括号之间的模式所匹配到的字符 \2 表示从左侧起第2个左括号以及与之匹配右括号之间的模式所匹配到的字符,以此类推 & 表示前面的分组中所有字符
#!/usr/bin/env bash
------------------------sleepAndExecDebug() {
set +x
sleep 1
set -x
}
tee test.reg4.txt > /dev/null <<EOT
Hello world Hello world
Heiii world Heiii world
Hello world Heiii wwwww
EOT
------------------------sleepAndExecDebug
grep "\(He\)" test.reg4.txt
------------------------sleepAndExecDebug
grep "\(He\).*\1" test.reg4.txt
------------------------sleepAndExecDebug
grep "\(He\).*\(wo\).*\2" test.reg4.txt
扩展正则表达式
(1)字符匹配: . 任意单个字符 [] 指定范围的字符 [^] 不在指定范围的字符 次数匹配:
- :匹配前面字符任意次 ? : 0 或1次
- :1 次或多次 {m} :匹配m次 次 {m,n} :至少m ,至多n次
(2)位置锚定: ^ : 行首 $ : 行尾 <, \b : 语首 >, \b : 语尾 分组:() 后向引用:\1, \2, …
(3)总结 除了<, \b : 语首、>, \b : 语尾;使用其他正则都可以去掉\;
ack
# http://betterthangrep.com/documentation/
# http://codeseekah.com/2012/03/11/ack-vs-grep/
sudo apt install ack
# 速度非常快,因为它只搜索有意义的东西。
# 更友好的搜索,忽略那些不是你源码的东西。
# 为源代码搜索而设计,用更少的击键完成任务。
# 非常轻便,移植性好。
# 免费且开源
-c(统计)/ -i(忽略大小)/ -h(不显示名称)/
-l(只显文件名)/ -n(加行号)/ -v(显示不匹配)
文本搜索
ack hello
ack -i hello # -i, --ignore-case 屏蔽大小写
# -I, --no-ignore-case 不屏蔽大小写(默认)
ack -v hello # -v, --invert-match 反向匹配
ack -w hello # -w, --word-regexp 单词匹配
ack -Q 'hello*' # -Q, --literal 引用所有元字符; PATTERN 是文字
文件搜索
ack --line=1 # 输出所有文件第二行
ack -l 'hello' # 包含的文件名
ack -L 'print' # 非包含文件名
ack hello --pager='less -R' # 以less形式展示
ack hello --noheading # 不在头上显示文件
ack hello --nocolor # 不对匹配字符着色
ack -f hello.py # 查找全匹配文件
ack -g hello.py$ # 查找正则匹配文件
ack -g hello --sort-files #查找然后排序
ack --python hello #查找所有python文件
ack -G hello.py$ hello # 查找匹配正则的文件
ack配置
# 设置排序
--sort-files
#设置文件过滤
--python
--html
--js
--conf
# 设置显示
--noheading
# 定义新的文件类型
--type-set=conf=.conf
# 智能识别大小写
--smart-case
# 设置以less形式展示,设定less参数
--pager=less -R -M --shift 5 -i
ag
sudo apt-get install silversearcher-ag
ag main
ag "main("
ag "main\(" src
ag "main\(" --ignore-dir 3rdparty
ag "main\(" --ignore-dir 3rdparty --ignore-dir doc
ag "http" -l | xargs sed -i 's/http/https/g'
grep -ri "http" * -l | xargs sed -i 's/http/https/g'
ag 另外其他很有用的選項是
ag -i 使用大小寫不敏感的匹配方式
ag -w 全詞匹配
ag -G ".+\.java" 搜索 java 類型的檔案
ag -l 顯示有匹配的檔案路徑
ag -L 顯示沒有任何匹配的檔案路徑
ag -v 反向匹配,將匹配到的資料排除
ag 搭配正規表達式
ag ^abc log.txt
ag abc$ log.txt
ag abc[0-9] log.txt